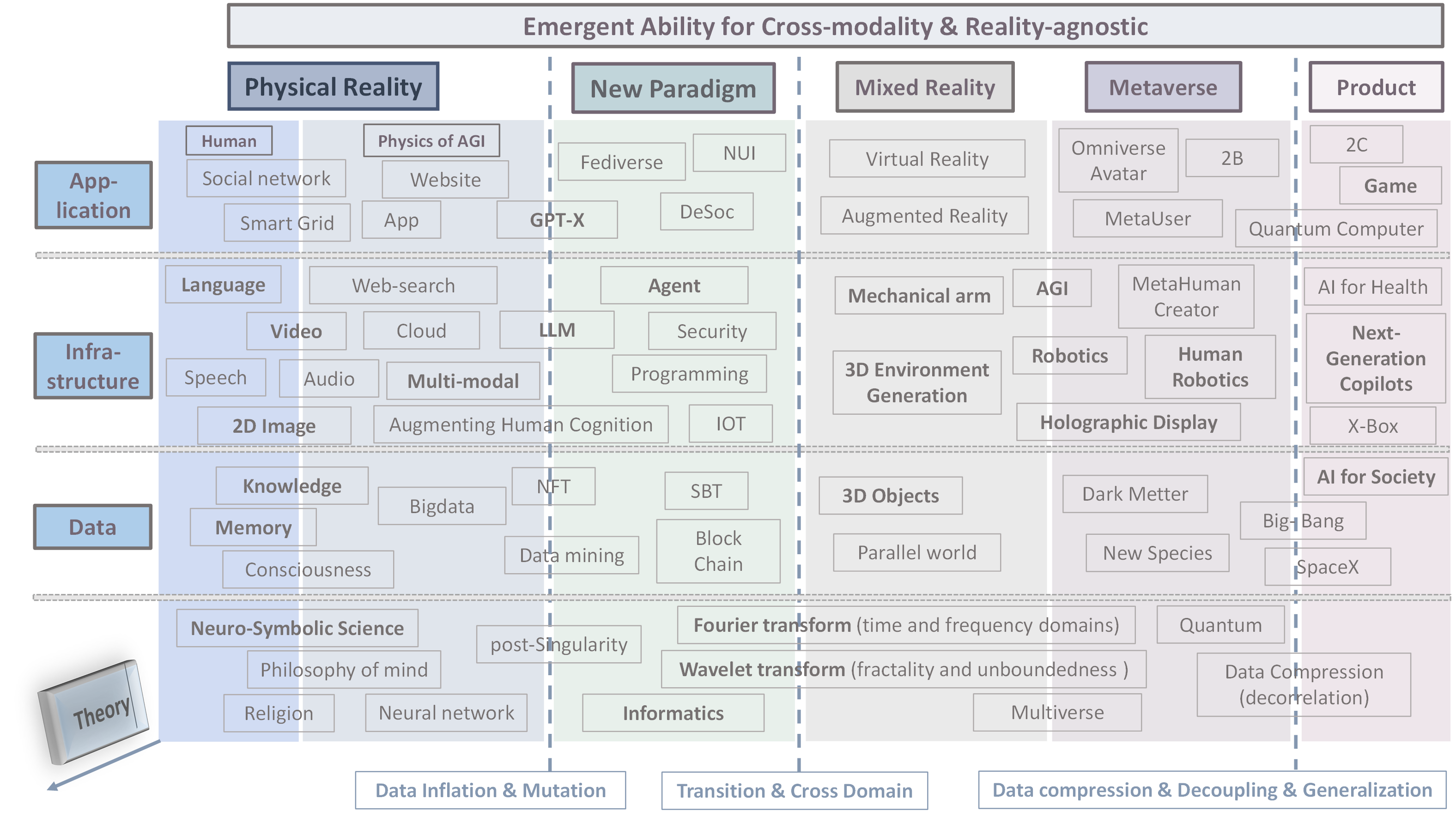
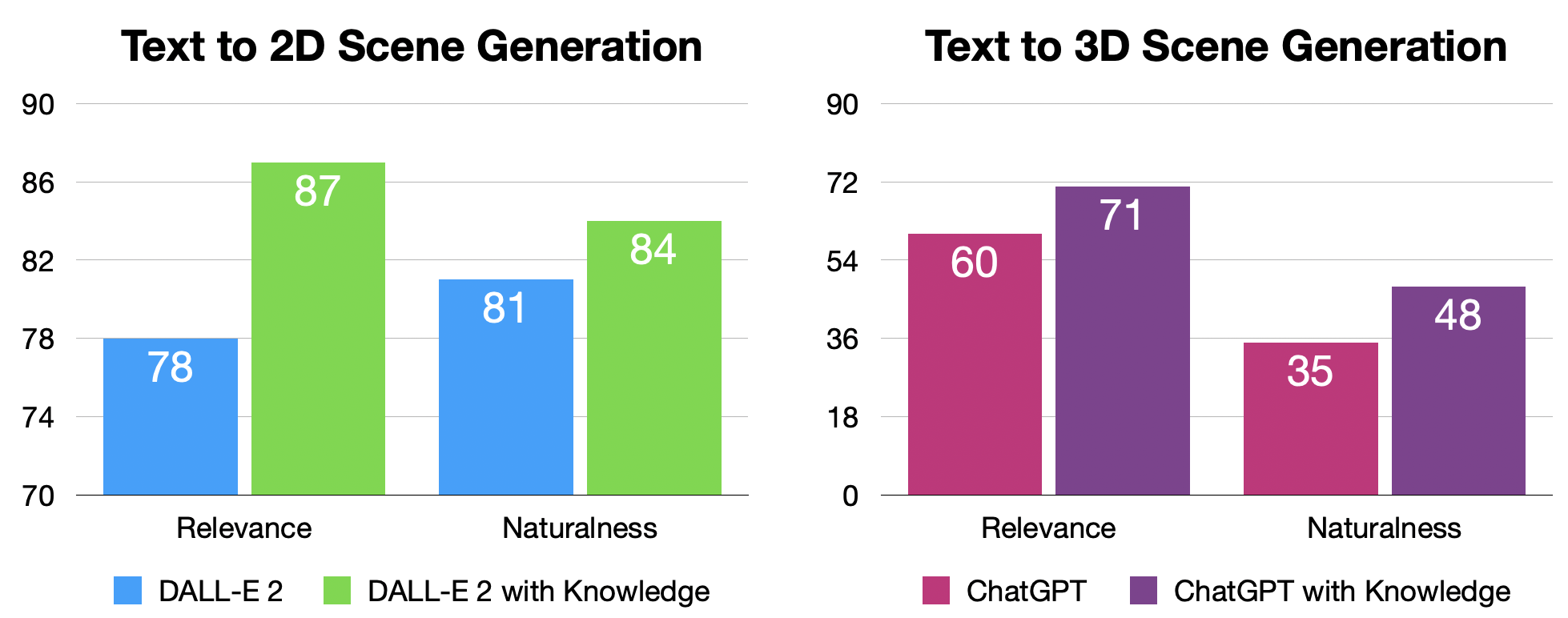
Despite the growing adoption of mixed reality and interactive AI agents, it remains challenging for these systems to generate high-quality 2D/3D scenes in unseen environments. The common practice requires deploying an AI agent to collect large amounts of data for model training for every new task. This process is costly, or even impossible, for many domains. In this study, we develop an interactive agent that learns to transfer knowledge-memory from general foundation models (e.g., GPT4, DALL-E) to novel domains or scenarios for scene understanding and generation in the physical or virtual world. The heart of our approach is an emerging mechanism, dubbed Augmented Reality with Knowledge Inference Interaction (ArK), which leverages knowledge-memory to generate scenes in unseen physical world and virtual reality environments. The knowledge interactive emergent ability (Figure 1) is demonstrated as the observation learns i) micro-action of cross-modality: in multi-modality models to collect a large amount of relevant knowledge-memory data for each interaction task (e.g., unseen scene understanding) from the physical reality; and ii) macro-behavior of reality-agnostic: in mix-reality environments to improve interactions that tailor to different characterized roles, target variables, collaborative information, and so on. We validate the effectiveness of ArK on the scene generation and editing tasks. We show that our ArK approach, combined with large foundation models, significantly improves the quality of generated 2D/3D scenes, compared to baselines, demonstrating the potential benefit of incorporating ArK in generative AI for applications such as metaverse and gaming simulation with emergent ability works invisible.
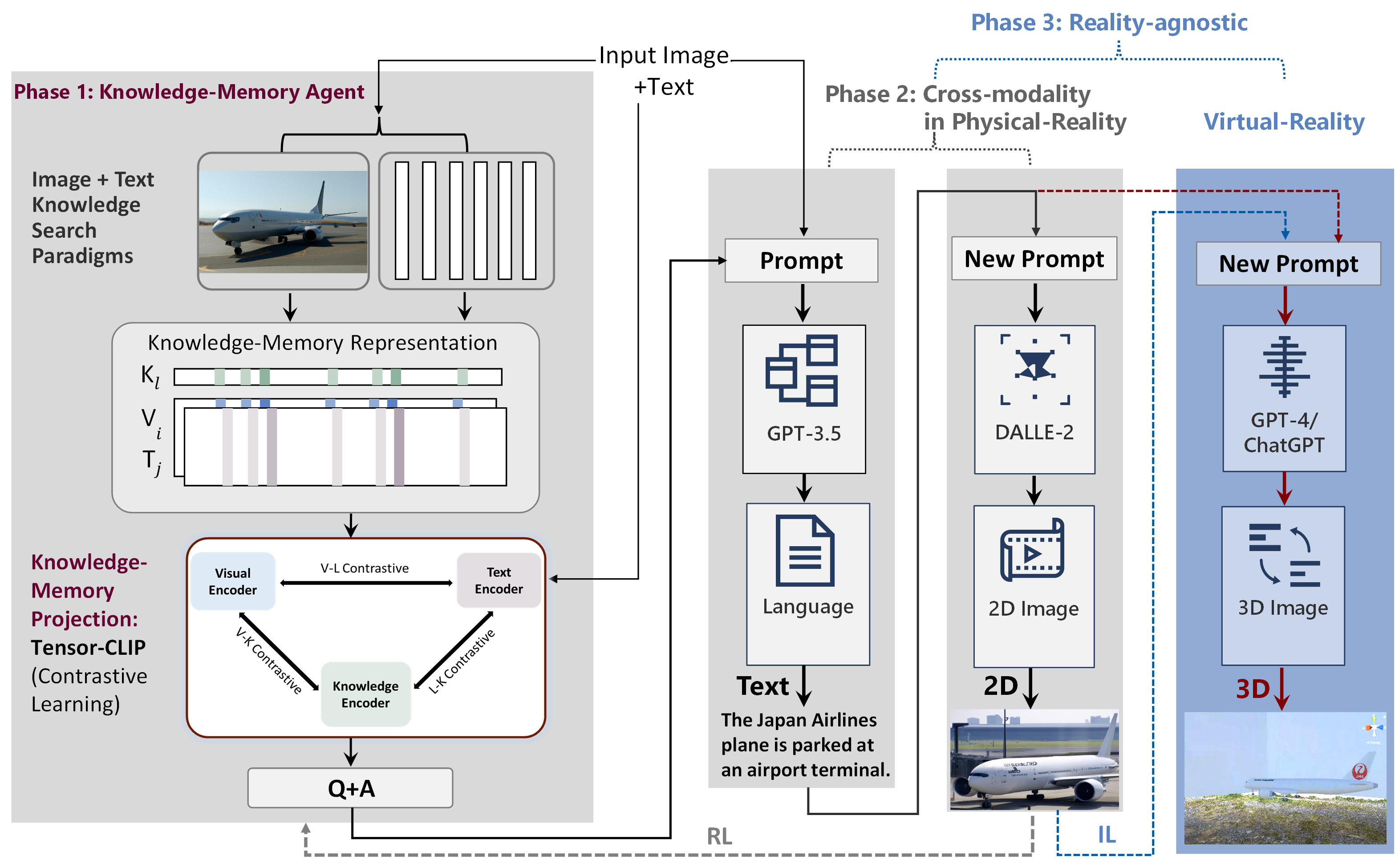
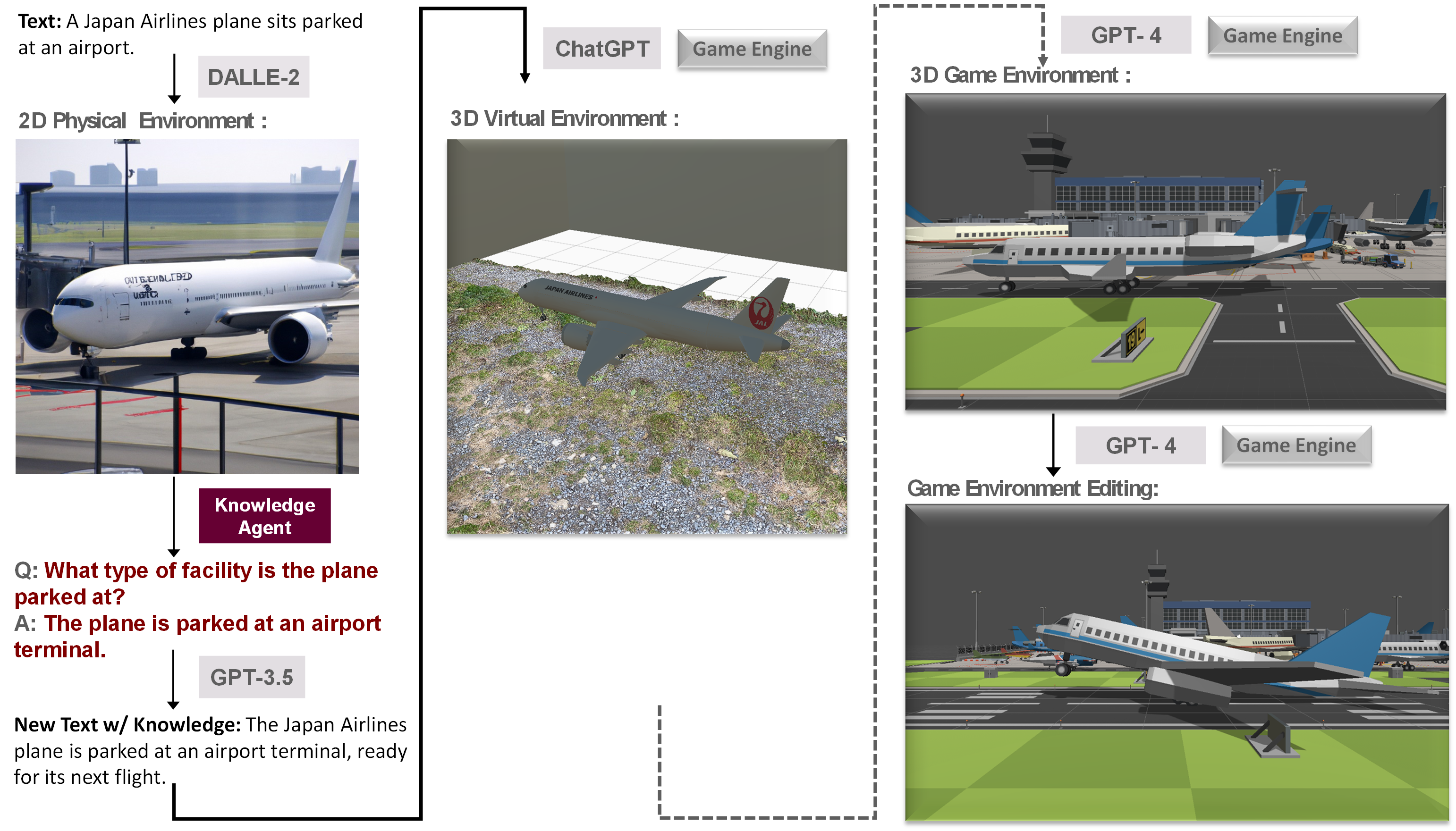
Flowchart of ARK: Reinforcement Learning that Connects DALL-E Prior and GPT4/ChatGPT Program Synthesis Generation for 3D Scene Generation.
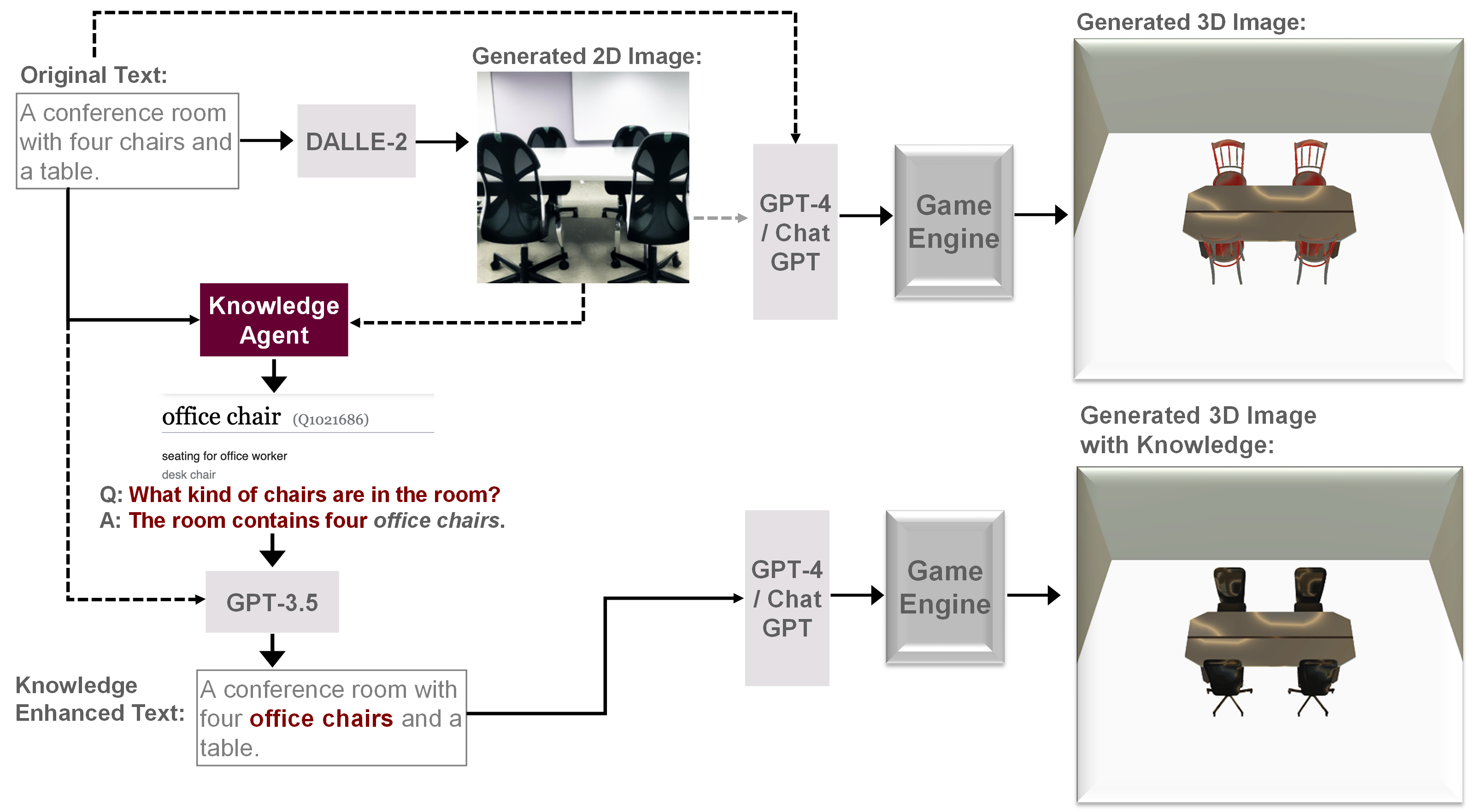
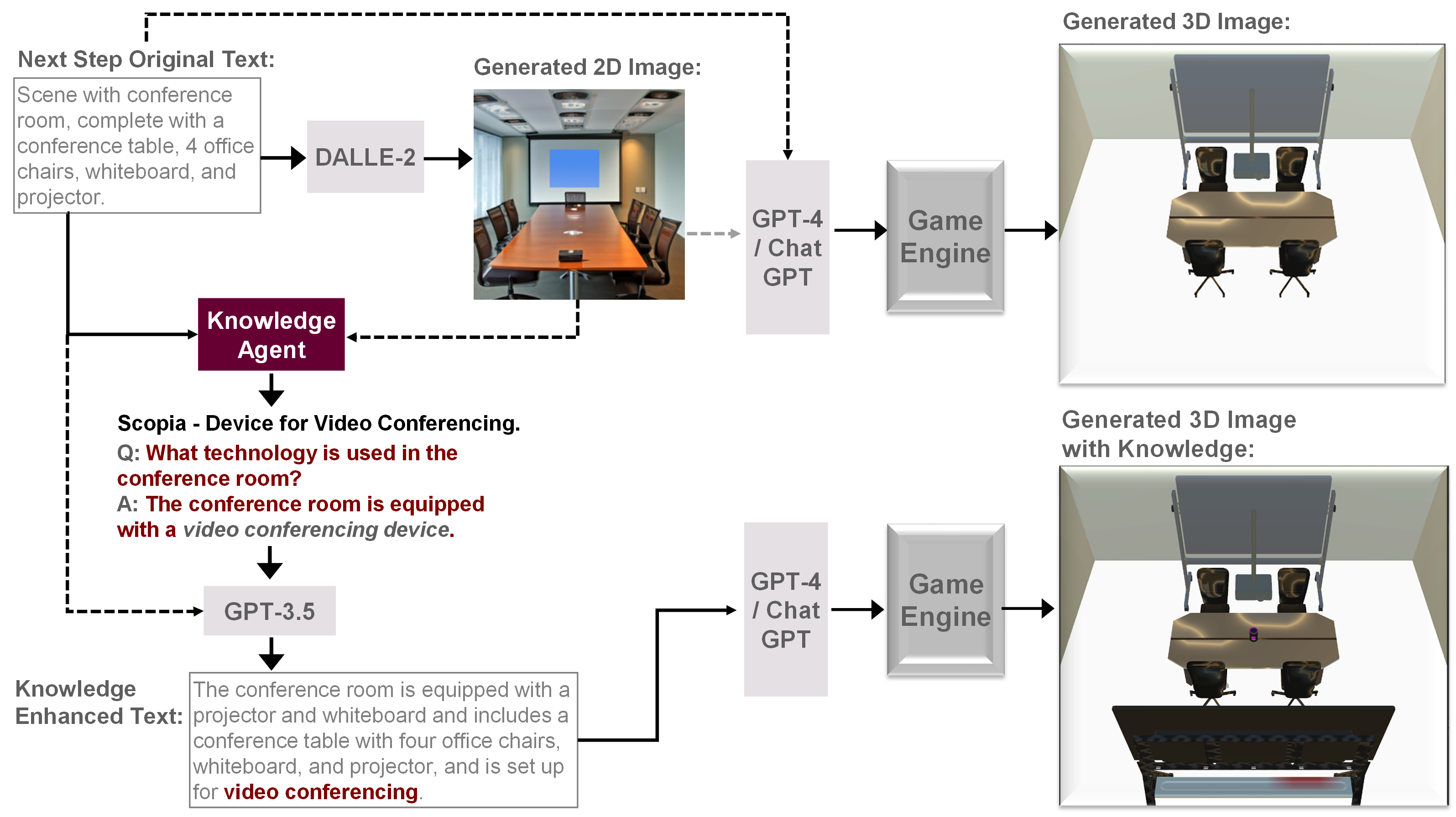
ARK combines entity knowledge from the web and knowledge of 2D world to enhance 3D scene generation.

@article{huangark2023,
author = {Qiuyuan Huang and Jae Sung Park and Abhinav Gupta and Paul Bennett and Ran Gong and Subhojit Som and Baolin Peng and Owais Khan Mohammed and Chris Pal and Yejin Choi and Jianfeng Gao},
title = {ArK: Augmented Reality with Knowledge Interactive Emergent Ability},
journal = {arXiv preprint },
year = {2023},
}